Epistemology
A private open source platform for your local text AI

Language learning models are powerful tools you should feel in control of. This project was created to be a middle ground between bare bones CLI usage of llama.cpp and AI interfaces that are so complex or black boxes they feel untrustworthy. It offers a number of ways it aims to be private that may appeal to you:
Unlock seamless integration with a local HTTP API for AI completion and embedding. Build frontends with whatever tech you like backed by a simple and understandable backend. The API's clarity and simplicity ensure complete visibility into every aspect of its operation.
Epistemology comes with a default UI for text completion, but makes it easy to replace with your own personal web frontend.
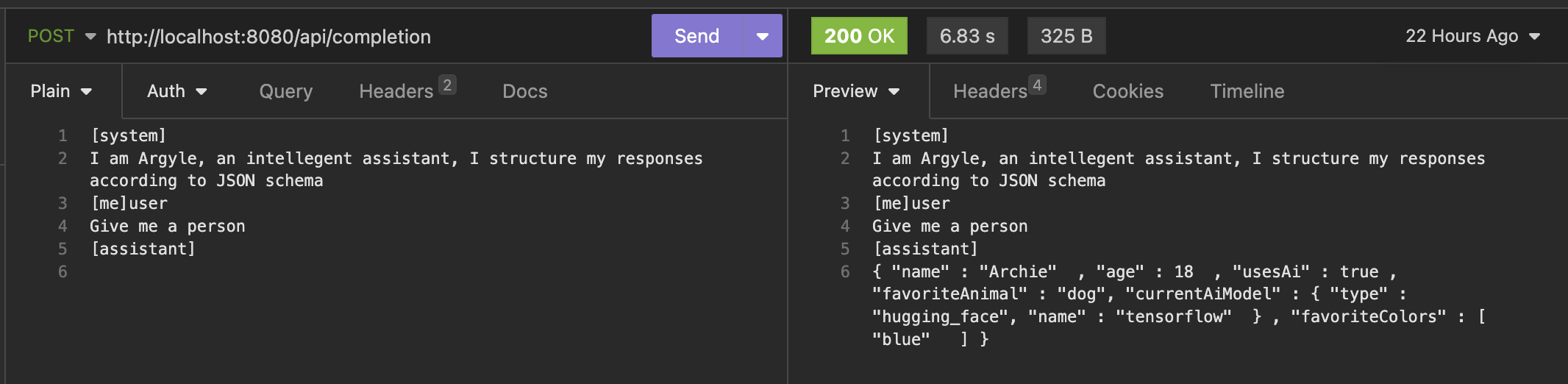
Constraining AI outputs using grammars is very powerful, Epistemology natively supports using JSON schema files as grammars so you can get useful structured output for programmatic interfaces.
Install llama.cpp. If you are using Windows, choose the appropriate zip depending on if using Nvidia Cuda or AMD OpenCL CUBlas. If you are using mac, check out how to build here. If you are using other unix systems, you can build from source according to Llama.cpp's website.
Download a GGUF model such as TheBloke/phi-2-GGUF. Any llama.cpp compatible GGUF you know can run on your machine will do.
Download epistemology server binaries (macOS, Linux, Windows)
or
Build from
cargo install epistemology
Run the server
epistemology -m ../llama.cpp/phi-2.Q2_K.gguf -e ../llama.cpp/main -d ../llama.cpp/embedding
Serving UI on https://localhost:8080/ from built-in UI
Listening with GET and POST on https://localhost:8080/api/completion
Examples:
* https://localhost:8080/api/completion?prompt=famous%20qoute:
* curl -X POST -d "famous quote:" https://localhost:8080/api/completion
* curl -X POST -d "robots are good" https://localhost:8080/api/embedding
Find more details by running
epistemology --help
or visiting the project page at https://github.com/richardanaya/epistemology/.
Be in control of your AI.
Powered by Rust.
MIT licensed.
Github.